In 2017, a Google Brain paper with a quietly confident title rewired how the world thinks about sequence modeling. Attention Is All You Need didn’t just introduce a better architecture – it made everything that came before it feel like scaffolding we’d been waiting to tear down.
Seven years on, transformers underpin virtually every frontier model you can name: GPT-4, Gemini, Claude, Mistral, LLaMA. The question is no longer whether attention works. The question worth asking now is: do we actually understand why it works as well as it does?
The Problem Attention Was Solving
Before 2017, the dominant approach to sequence tasks was the recurrent neural network. RNNs process tokens one at a time, left to right, threading a hidden state through the sequence like a baton being handed down a very long relay. The hidden state is supposed to carry everything the model needs to remember — context, dependencies, meaning – but the further back that information originated, the harder it is to preserve.
LSTMs helped. Gated mechanisms gave the model some control over what to forget and what to keep. But the fundamental bottleneck remained: all history had to be squeezed through a fixed-size vector. For long sequences, this is a lossy compression problem, and lossy compression is the enemy of coherence.
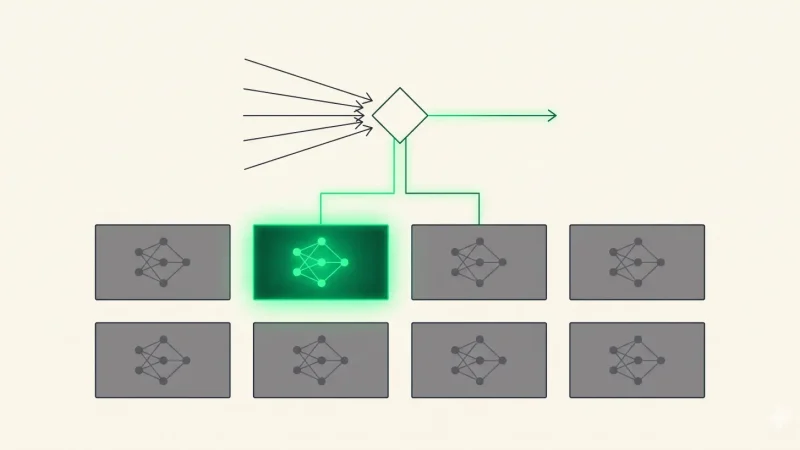
The attention mechanism, first proposed as an add-on to seq2seq models by Bahdanau et al. in 2015, offered a different approach. Rather than forcing memory through a bottleneck, why not let the model look directly at any previous token when it needs to? Allow each step to query the full history and weight what’s relevant.
The 2017 paper took this idea and made it the whole architecture. No recurrence. No convolutions. Just attention, layered and parallelized.
What Att We Don’t Fully Understand
Here’s where honesty requires a bit of humility.
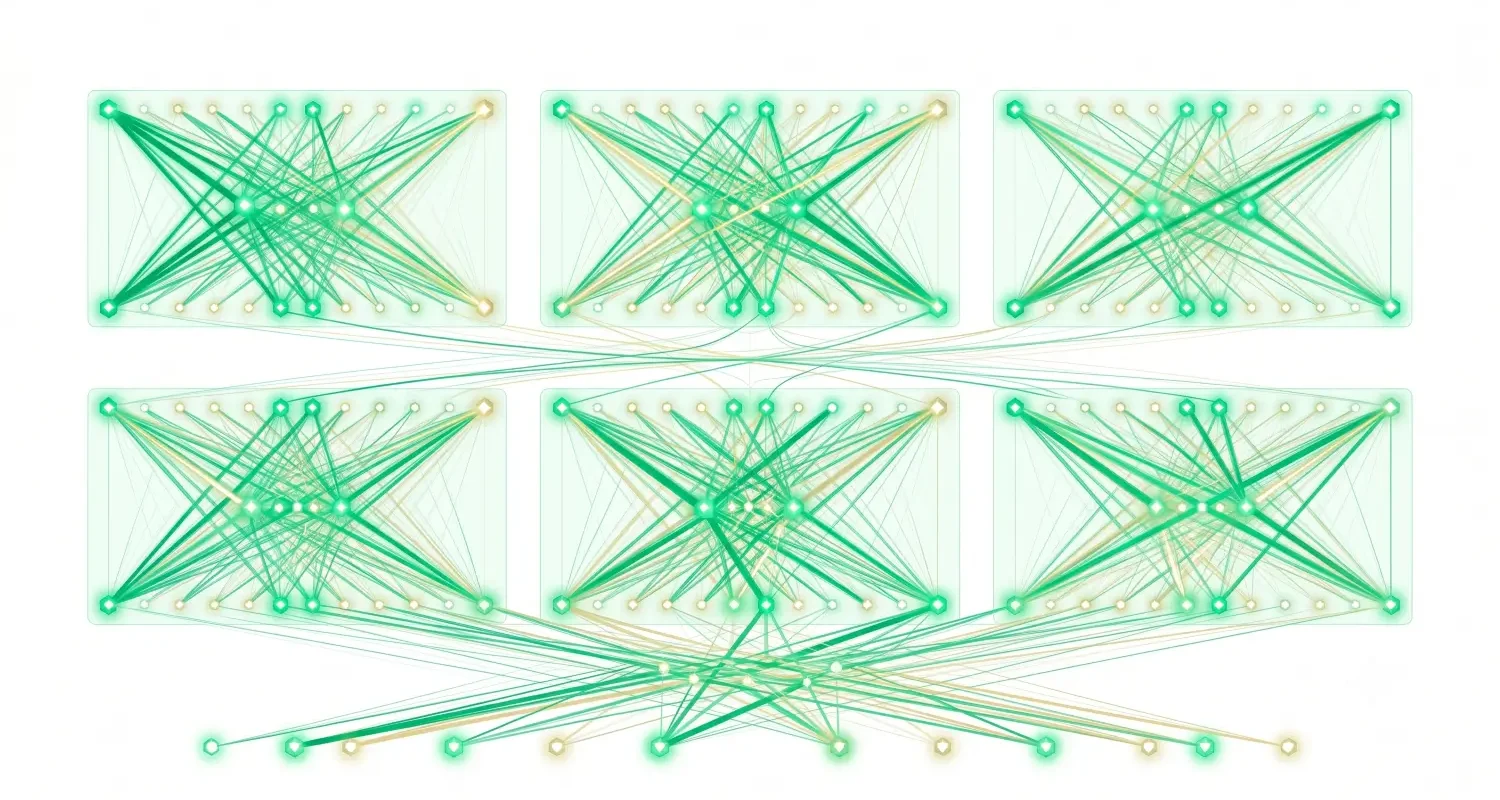
We can describe the mechanics of attention precisely. We can watch what individual heads appear to learn – some heads in BERT famously attend to the previous token or to sentence-boundary tokens with remarkable consistency. Probing experiments can tell us whether a model’s representations encode part-of-speech, syntactic structure, or named entity type.
What we don’t have is a clean mechanistic story that connects these observations to downstream task performance. Why does scaling the number of heads and layers translate so smoothly into capability? Why does the quadratic attention mechanism, which seems like it should struggle on very long sequences, still outperform alternatives in practice? Why do transformers seem to develop something that looks like compositional reasoning, when nothing in their training objective explicitly demands it?
Mechanistic interpretability – work coming out of Anthropic, DeepMind, and academic labs – is making real progress on this. The concept of attention circuits, induction heads, and superposition of features gives us a vocabulary for reverse-engineering what’s happening inside specific layers and heads. But we’re still reading individual sentences in a book we haven’t fully mapped.
Why It Still Matters to Ask
One could argue this is an academic concern. The models work. Ship them.
But understanding why attention is so effective has practical stakes. If we knew more precisely what properties of attention cause emergent capabilities, we could design architectures more intentionally rather than scaling and hoping. We could debug failures more systematically. We could make safety guarantees grounded in mechanism rather than empirical observation.
The history of engineering is full of things that worked before we understood them – steam engines predated thermodynamics, aspirin predated COX inhibition, the whole of classical computing ran on silicon for decades before quantum effects became relevant. But in each case, the mechanistic understanding, when it came, unlocked a new generation of design.
Attention is all you need — at least for now. Understanding why might be everything we need next.